


The “EU First” Tech Agenda
Plus: EU AI Act enforcement, data in AI, copyright guidance, and knowledge distillation

Did you forget about DeepSeek? Stargate? OpenAI Operator? Musk’s bid for OpenAI? TikTok’s OmniHuman? There are too many new things happening in AI – and that just covers 2025! This newsletter isn’t really about covering AI news, it’s about synthesizing what these developments mean for AI governance professionals.
In today’s edition (6 minute read):
The “EU First” Tech Agenda
EU AI Act Hits First Compliance Milestone
Understanding the Data in AI
US Copyright Guidance on AI
Knowledge Distillation in 2025
1. The “EU First” Tech Agenda

The EU AI Act passed amidst much criticism that the new law would stifle innovation. However, in the wake of the September 2024 Draghi Report and the “America First” agenda taking shape in the US, it appears that the EU is ready to be an innovation leader.
Over the past week, the AI Action Summit in Paris sought to position the EU towards a more innovative approach to AI. This comes just days after French President Emmanuel Macron lamented that Europe was not in the AI race; lagging behind China and the US. France, along with Germany and Italy, sought to soften some elements of the EU AI Act like provisions pertaining to foundational models. Macron’s comments come at a time when France is clearly positioning itself as the European AI leader, with an expected €109 billion in private investment for AI and Mistral’s new le Chat app. During the Paris Summit, European Commission (EC) President Ursula von der Leyen announced a plan to invest €200 billion in the European AI industry. Approximately €50 billion would come from the EU, with the rest of the money coming from the private sector. Meanwhile, the EC is withdrawing the proposed AI Liability Directive from consideration, citing “no foreseeable agreement.” The EC noted it may consider “whether another proposal should be tabled or another type of approach should be chosen.”
Our Take: This is the first time we have seen a serious pro-innovation movement in the EU.
While the last week has shown that the EU is eager to be a technology powerhouse, it will not happen overnight and must contend with a tech sector that is woefully behind both the US and China. However, with the Trump Administration taking a more isolationist approach in the US and Vice President JD Vance admonishing the EU’s “excessive regulation,” the EU has picked the prime time to step into the tech spotlight.
2. EU AI Act Hits First Compliance Milestone

Despite the EU’s recent AI innovation renaissance, the EU AI Act looms over the bloc’s tech ambitions. Just six months after the EU AI Act entered into force, the first set of obligations are coming to effect. Beginning on February 2, 2025, organizations needed to comply with the EU AI Act’s first five articles. These provisions include the prohibited AI practices and AI literacy requirements. Shortly after the February 2nd compliance deadline, the EC published guidance to help clarify the scope and obligations under the law. The new guidelines are a result of stakeholder input solicited throughout last year. Notably, this guidance is non-binding and open to interpretation from the Court of Justice of the European Union.
The EC’s Draft Guidelines on Prohibited AI Practices provides a detailed explanation for eight types of AI systems that are banned under the EU AI Act. These systems include those used to assess or predict the risk of a person committing a crime and social scoring. Systems that are used to infer emotions in the workplace or educational settings have a narrow exemption for medical or safety purposes. The Guidelines on the Definition of AI provide an in-depth analysis of the definition of AI under the EU AI Act. It clarifies the seven elements of the definition, such as the system’s level of autonomy and adaptiveness after deployment. It also describes systems that fall outside of the definition’s scope, such as those that improve mathematical optimization or basic data processing systems. The EC also published the Compilation of AI Literacy Practices, which serves as a non-exhaustive repository for AI literacy practices that are implemented or planned across varying organizations. The repository accounts for the size of the organization and its relevant economic sector(s). The EC notes that it intends to update it regularly.
What’s Next: There are two more major deadlines for the EU AI Act in 2025. The first is May 5, when the EC is required to publish the Codes of Practice for General Purpose AI (GPAI) Models. A third draft of the GPAI Codes of Practice is expected on February 17, though there appears to be some contention over the role of external evaluators in the AI training process. The new draft or final Codes may also reflect a more innovative approach based on the EU’s recent pivot. The second is August 2, when obligations for GPAI Models and enforcement penalties take effect. Certain obligations for EU Member States and the EC will also take effect.
3. Understanding the Data in AI

Data governance is a key component of responsible AI governance. However, “data” is not a monolithic concept within AI systems. From the massive datasets collected for training large language models (LLMs), to user feedback loops that refine and improve outputs, multiple “data streams” flow through any modern AI application.
Many organizations assume that if they rely primarily on third-party AI models, they may be exempt from extensive data governance responsibilities. However, even AI deployers often must comply with data-related obligations—especially as AI regulations around transparency, privacy, and intellectual property continue to evolve.
In Trustible’s latest blog post, we explore six key data categories that are relevant to AI systems, and how data governance will differ for each category:
Pre-Training Data
Fine-Tuning & RLHF Data
RAG/Agent-Integrated Datasets
Model Inputs
Model Outputs
User Feedback
Read our latest blog post here.
4. US Copyright Guidance on AI

While the legal status of using copyrighted works as training data is still being litigated (with a recent ruling in favor of content creators making waves in the legal world involving Thomson Reuters), the US Copyright Office recently announced new guidance to clarify conditions under which AI generated content can receive copyright, and other intellectual property protections. Their core finding is that AI generated content that is further modified by humans, or human content that is assisted by AI, is still eligible for copyright protections. However, they find purely AI generated content, and using prompts alone without more manual human modifications, is not eligible for copyright. They acknowledge that the ‘amount of AI’ used can still vary, and that more work is necessary to define acceptable use on a case-by-case basis. Here’s a quick overview, as summarized by Cassie Kozyrkov:
Your Creative Edits = ✅ Copyrightable
Your Creative Edits + AI Output = ✅ Copyrightable
Unedited AI Output = ❌ Not Copyrightable
Your Prompts + Unedited AI Output = ❌ Not Copyrightable
This change is arguably one of the most balanced pro-innovation AI policies we’ve seen recently as it both encourages ‘human in the loop’ activities, while also encouraging AI adoption in various creative industries. It’s very much aligned with existing standards for derivative works and prevents the potential for IP trolls generating massive amounts of content and then claiming infringement on anything similar. Rules like this can provide clarity and prevent controversies like the one currently roiling Hollywood where Generative AI use in The Brutalist almost led to its disqualification from the Oscars.
Our Take: While legislation and regulations may set a ‘floor’ for AI governance activities, organizational liability will be the biggest market-driver of AI governance practices. Giving clarity that AI outputs can be protected under certain circumstances will remove many legal restrictions and barriers for AI adoption across a wide range of industries.
5. Knowledge Distillation in 2025
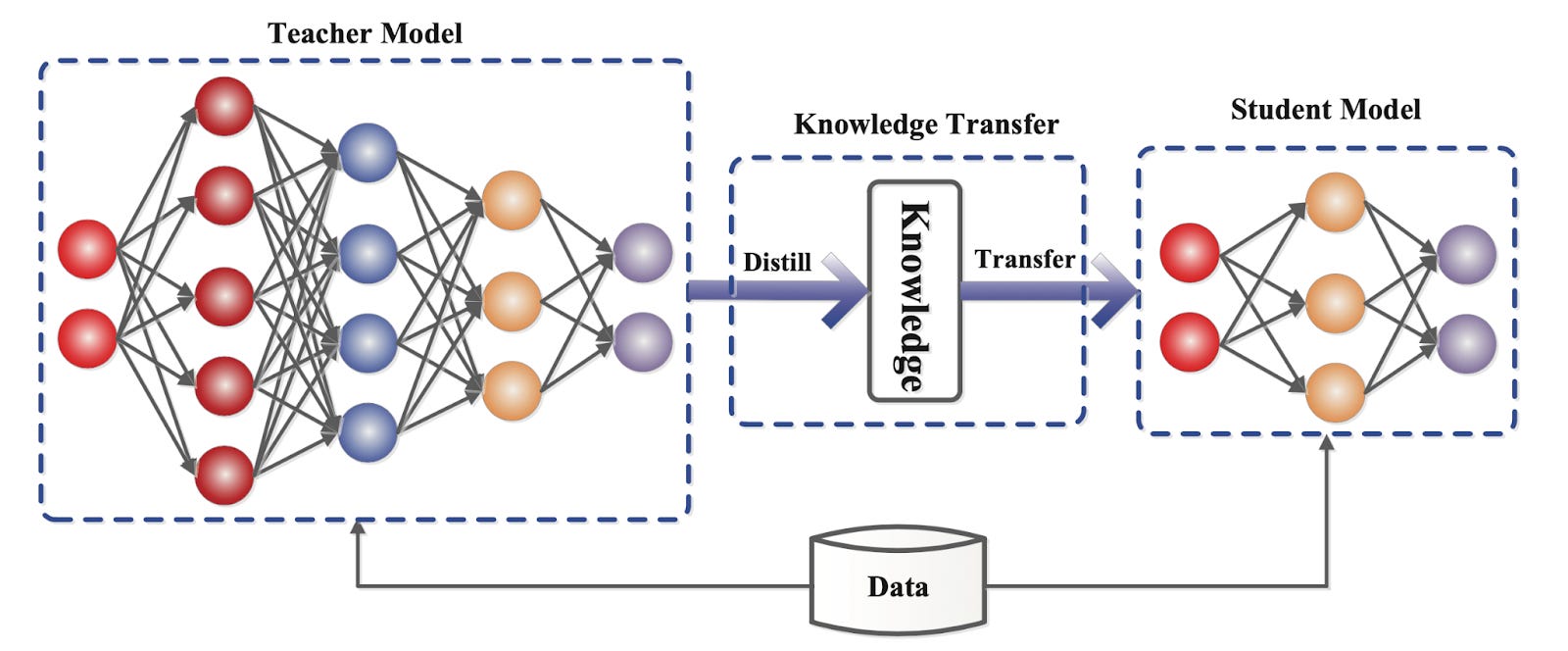
Source: https://arxiv.org/pdf/2006.05525
Knowledge distillation has made headlines because DeepSeek-R1 has been effective in training smaller models and because the model itself was allegedly built with the help of OpenAI’s models. However, distillation is not new; it was popularized in machine learning nearly a decade ago and early related experiments were conducted in the mid-2000s. LLMs like Gemini-1.5 Flash have already been trained with this methodology.
Before exploring how distillation can impact the broader AI ecosystem, it is important to understand some basics. Distillation is the process of using a larger “teacher” model to train a smaller “student” model. Consider a hypothetical task of classifying cat breeds from images. The teacher model is a blank slate that is trained on a large dataset of cat images and breed labels. Through this process, the model learns useful signals that indicate a particular breed (e.g. fur color and ear shape). The student model can then be trained to specifically recognize these important signals, which can be done with a more compact model. In practice, we do not know ahead of time what qualifies as “important signals,” which is why the student model can not be trained directly. In the context of LLMs, the teacher model can be used to generate “chain-of-thought” examples that show how the model “reasoned” before arriving at a final answer. The student model can learn to replicate the examples and encode the reasoning abilities that the larger model learned from scratch.
We predicted that 2025 will be a big year for smaller, domain specific models and distillation can play an important role here. Smaller models can be fine-tuned using raw data, but if this data is supplemented with “distilled knowledge” from larger models the results will be more powerful. At the same time, many developers do not allow their models to be used to train other models. For instance, the Terms of Service for OpenAI and Anthropic do not allow their products to be used to train models that will compete with their service. Similarly, Llama’s license requires any model that uses its output to include “Llama” in its name. Given these restrictions, the exact role of distillation remains to be seen.
Key Takeaway: Knowledge distillation is the process of compressing information from large models into smaller ones. It will continue to be an important tool as the need for smaller models rises due to requirements like energy efficiency and on-premise hosting. However, given the restrictions on using model outputs for training from major developers, the exact places ways this technique will be applied by down-stream users remains unclear.
*********
As always, we welcome your feedback on content and how to improve this newsletter!
AI Responsibly,
- Trustible team