


Unpacking Open-Source AI, Democratic AI, AI Agents, and more
Plus analysis on AI incidences and how the insurance sector demonstrates the difficulty of regulating AI.

Hi there! While summer vacation season may be in full swing, AI news has not let up. In today’s edition:
How do we define Open Source AI
What are risks associated with AI Agents
Uncertainty in the democratic approach to AI rules
What to do when AI goes wrong
Insurance Sector Demonstrates the Difficulty of Regulating AI
1. Unpacking the definition of “open-source”

The newly released Llama-3.1 model from Meta has been promoted as open-source, but the actual license falls short of the actual definition. Open Source is a broad term, derived by the Open Source Initiative (OSI), that captures a class of licenses (e.g. Apache 2.0 and MIT) that allow for free, unrestricted use for software with access to the source code. In contrast, Llama models come with restrictions on commercial use and require all users to agree to their acceptable use policy.
Even for model’s released under an OS license (like many of Mistral’s models), there is an open question about how the definition of open-source AI should differ from the one for traditional software (OSI is currently working on this challenge). The difference stems from the four components necessary that produce a final model:
Model Code (Provided by open-weight models)
Model Weights (Provided by open-weight models)
Training Code (Often not provided)
Training Data (Rarely provided)
While Model Code and Weights are sufficient to “use” the system without restrictions, they are insufficient to properly “study and inspect” the system. Without access to the training data, it is difficult to answer questions like: was the model trained on toxic language or the most recent version of SNOMED taxonomy?
The working definition of open-source AI captures all four components, but stops short of requiring a full release of training data, requiring instead detailed information that could be used to produce the same or a similar dataset (neither Mistral nor Meta provide this). In our AI Model Ratings, we already evaluate the transparency of models along similar dimensions and hope that the final definition of “Open Source AI” will standardize language across the industry,
Our Take: “Open-Source” branding is applied to models that are actually limited use or only “open-weight”. A lack of clear distinctions between these concepts obfuscates the limited release of information about the training data and process. The Open Source Initiative is working on an official definition of open-source AI that should hold organizations to stricter standards.
2. Uncertainty in the Democratic Approach to AI Rules

Last week, Sam Altman wrote an editorial in the Washington Post that argued for why democratic values in AI should succeed over authoritarian ones. His main point centered on a U.S.-led coalition of global democracies to steer the future of AI and innovation. Yet, while overarching goals and vision can help unite likeminded, democratic nations, a deeper analysis highlights the seemingly unpopular and uncertain path forward with AI regulations.
The EU AI Act will enter into effect later this week. The AI Act’s prescriptive approach has raised concerns over the negative impacts on innovation and an overcomplicated bureaucratic process. The AI Act also threatens to fracture the global marketplace, as evidenced by companies refusing to release certain products in the EU, such as Apple Intelligence. Conversely, a recent string of elections add more uncertainty into the AI regulatory landscape. In the U.K., the newly-elected Labour government is moving forward with AI regulations, but their legislative approach is unclear. In India, the final elements of the Digital India Act remain uncertain after Prime Minister Narendra Modi’s party underperformed in recent elections.
As for the U.S., it is still unclear which direction it may take on AI and the lack of clear federal policy may undermine our technological advantage. Moreover, political rhetoric in the U.S. that amplifies isolationist and protectionist policies threatens to minimize our role as a global leader on AI policy.
Our Take: AI laws are still being written and are ripe for input, but the window for global alignment is closing. It will require a coordinated approach from governments and industry to establish a more cohesive set of standards that promote democratic values and innovation. Without a clear vision or strong advocacy, we risk creating competing standards that restricts existing tech companies, places high entry barriers for new companies, as well as fails to ensure that AI promotes values that respect human rights and civil liberties.
3. The Rise of AI Agents: Balancing Autonomy and Risk

AI Agents are systems that autonomously interact with their environment, plan, and perform tasks. While not new, Large Language Models (LLMs) have significantly enhanced their capabilities. Given a request to “Plan a dinner party”, a very powerful agent would generate a plan using an LLM and execute the steps: asking the user exactly who to invite, sending out invitations, placing an order for the groceries and so on. In practice, most current AI Agents would only handle 1-2 of those steps at a time, with developers defining some parameters for each task. With the increased autonomy and flexibility provided by agents, come new and heightened risks:
Data Privacy: Agents may be given access to a larger number of data sources than a simple RAG system, increasing the likelihood that sensitive information gets leaked using the system.
Excessive Agency: When agents have “write” access to other systems (e.g. send an email or modify a database), errors, like hallucinations, made by the system may be consequential.
Indirect Prompt Injections: Agents can be manipulated by malicious actors that insert bad instructions into a data source and force the model to execute them. For example, an agent that reads and responds to emails can receive a malicious email instructing it to send spam to the entire contact list (Source).
Auditability: Agents execute on multi-step plans automatically, which can make it harder to explain the system’s decisions and investigate problems. (Additional Discussion).
Evaluation: Chatbots and RAG Systems are difficult to evaluate because of the broad range of possible user inputs; AI Agents add another layer of difficulty because they interact with a broad range of ever-changing, external systems. (Additional Discussion)
Our Take: LLMs have enabled AI Agents that can take multi-step actions with reduced human supervision. However, organizations will need to decide between the increased flexibility provided by these systems and the risks around Privacy, Security, Auditability and Performance.
4. What to do when AI goes wrong
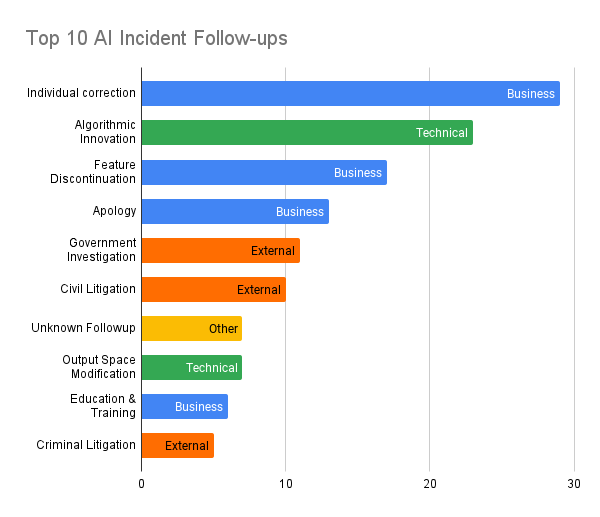
AI incidences are an under-researched area. Most organizations don’t have a complete understanding of what is considered an AI incident or how to respond if they occur. Trustible, leveraging resources such as the AI Incident Database (AIID) and the AI Vulnerability Database (AVID), published an analysis of AI-related incidents and what common tactics organizations employ while responding to these incidents. Here’s a quick summary:
Trustible reviewed a random sample of 100 incidents from AIID, examining follow-up actions from news articles and company press releases, categorizing responses into technical, business, and external actions.
Common Responses:
Business: Individual Correction: Most often, companies address incidents on a short-term basis, such as paying compensation without implementing systemic changes.
Algorithmic Innovation: About 23% of incidents involved technical changes to the actual AI system, such as modifying training data or algorithm outputs to prevent future issues.
Feature Discontinuation: In 16% of cases, companies discontinued problematic features, aligning with responsible AI practices of retiring harmful systems.
Incidents are not a one-size-fits all. Organizations often responded with several simultaneous actions such as business corrections (compensation) and algorithmic innovation (modifying the model), combining short-term corrections with long-term preventive measures.
External Party Actions: Civil litigation and government investigations were common, particularly for incidents involving physical or financial harm. We expect that, as regulators increase their attention towards AI, these actions will only increase.
We’re grateful that groups like AIID and AVID exist to help the general public and researchers learn from past incidents to ensure organizations can better prevent future harm and ensure responsible AI deployment.
5. Insurance Sector Demonstrates the Difficulty of Regulating AI

Both the Colorado Division of Insurance (DOI), and New York Department of Financial Services (NYDFS) have advanced clear guidelines for testing AI systems in the insurance space. Colorado’s latest testing guidelines for life insurance outline a process for creating a ‘reference model’ in order to compare a model using external data sources, versus one that does not. It also describes several statistical techniques for inferring racial data, and determining acceptable bias thresholds. The latest circular from NYDFS outlines a similar approach, albeit without explicitly statistical thresholds defined in the circular itself. The NYDFS circular isn’t limited to just life insurance, or AI use that leverages external data, making its impact far broader.
The challenges both regulatory bodies have had in trying to establish clear, actionable guidelines for insurance providers may foreshadow the difficulties other regulatory bodies may encounter once they dig into the weeds of AI regulation. Both processes have received a lot of pushback from industry, and run into issues around how to determine proxy variables, infer protected attributes, regulate a wide variety of potential use cases, and try to translate legal concerns into statistical tests. These technical requirements are accompanied by mandatory AI risk management practices that the organization must adopt.
Our Take: Calculating bias and fairness metrics for AI can be hard, especially when you don’t have explicit information about protected classes or attributes. Defining what definitions of bias and fairness should be used may be even harder, especially once political and cultural aspects are added to the discussion. The difficulties of defining this in the insurance space likely foreshadow what other regulators will deal with in the years to come.
*********
As always, we welcome your feedback on content and how to improve this newsletter!
AI Responsibly,
- Trustible team